
Les grands modèles de langage (LLM) comme GPT-4 sont puissants, mais présentent une limite majeure : leur savoir est figé, restreint aux données publiques sur lesquelles ils ont été entraînés. Ils ne connaissent pas vos documents internes, vos informations confidentielles ni les données créées après leur dernière mise à jour. C’est pour combler cette lacune que la technologie Retrieval-Augmented Generation (RAG) a vu le jour.
Le RAG agit comme un pont, reliant en temps réel un LLM à vos sources de données privées et externes. Concrètement, il permet à une intelligence artificielle d’interroger vos bases de données, votre intranet ou vos documents métier avant de formuler une réponse. Le résultat ? Des solutions IA précises, fiables, contextualisées et toujours à jour, qui éliminent le risque de « hallucinations ». Ce guide détaille son fonctionnement, ses avantages concrets et les clés d’une mise en œuvre réussie.
Comprendre le fonctionnement du Retrieval-Augmented Generation
Le RAG associe la précision d’un moteur de recherche sémantique à la capacité de synthèse d’un LLM. Bien que sophistiqué en coulisses, le processus se divise en quatre étapes simples.
Étape 1 : L’ingestion et la préparation des données
Tout commence avec vos données. Qu’il s’agisse de documents PDF, de pages web, de bases de connaissances ou de transcriptions, ces informations sont d’abord centralisées. Elles sont ensuite découpées en segments plus petits (« chunks ») pour faciliter leur analyse. Chaque segment est transformé en une représentation numérique, un « embedding », qui capture son sens sémantique. Ces embeddings sont ensuite stockés et indexés dans une base de données vectorielle, qui devient la mémoire externe consultable de votre IA.
Étape 2 : La récupération (retrieval) de l’information pertinente
Lorsqu’un utilisateur pose une question comme « Quel est le statut du projet Alpha ? », sa requête est également convertie en vecteur sémantique. Le système utilise ce vecteur pour interroger la base vectorielle et trouver les segments de texte dont le sens est le plus proche de la question. Cette phase de récupération garantit que seuls les extraits les plus pertinents de vos documents sont utilisés pour élaborer la réponse.
Étape 3 : L’augmentation du prompt
Les segments de texte pertinents récupérés sont ensuite injectés dans le prompt (la consigne) envoyé au modèle de langage. Le prompt final regroupe à la fois la question initiale de l’utilisateur et le contexte sourcé extrait de vos propres données.
Par exemple :
« Contexte : [extraits pertinents des rapports sur le projet Alpha]. Question : Quel est le statut du projet Alpha ? »
Étape 4 : La génération de la réponse finale
Le LLM reçoit ce prompt enrichi. Grâce à ce contexte précis, il génère une réponse qui ne repose plus sur ses seuls savoirs génériques, mais bien sur les informations spécifiques que vous lui avez fournies. Le modèle peut ainsi synthétiser les données, répondre avec justesse et citer ses sources pour une transparence totale.
Les avantages concrets du RAG pour votre entreprise
Adopter un système RAG IA offre des bénéfices tangibles qui transforment l’accès et l’exploitation de l’information dans l’entreprise.
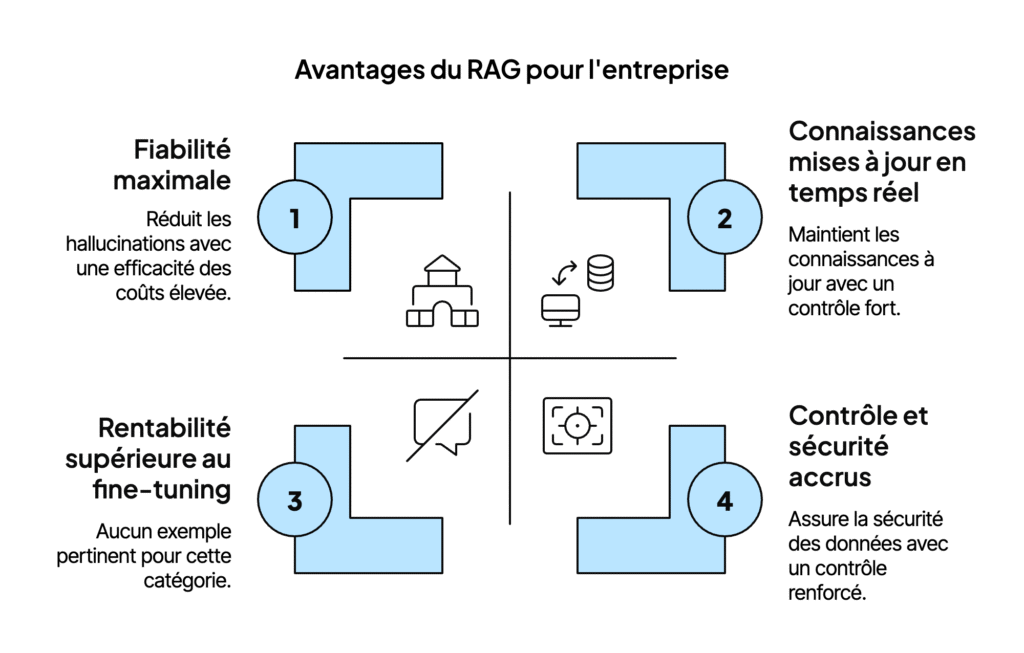
- Fiabilité maximale : dites adieu aux hallucinations de l’IA.
En s’appuyant sur des documents internes vérifiables, le RAG réduit drastiquement le risque d’informations inventées par le LLM. La précision et la confiance dans l’outil s’en trouvent renforcées. - Connaissances mises à jour en temps réel.
Contrairement au réentraînement d’un LLM, long et coûteux, la base de connaissances d’un RAG s’actualise en continu et à moindre frais. Il suffit d’ajouter de nouveaux documents pour que l’IA y ait accès immédiatement. - Contrôle et sécurité accrus.
Vos données privées restent dans votre écosystème. Le RAG permet une gestion fine des permissions, garantissant que le modèle ne consulte que les informations autorisées pour chaque utilisateur. Un point crucial pour la confidentialité et la gouvernance. - Une alternative plus rentable au réentraînement.
Comme l’indique une analyse de Microsoft, le RAG constitue une approche économique. Il évite les cycles de fine-tuning onéreux tout en assurant à votre IA des connaissances à jour.
RAG vs fine-tuning : quelle approche choisir ?
Le RAG et le fine-tuning (affinage) sont deux techniques pour spécialiser un LLM, souvent prépondérants à la création d’agents IA, mais ils répondent à des besoins différents. Comprendre cette distinction est essentiel pour faire un choix stratégique éclairé.
Le fine-tuning modifie les poids du modèle en le réentraînant sur un jeu de données spécifique pour lui apprendre un style, un ton ou un savoir-faire. Le RAG, lui, ne transforme pas le modèle ; il lui donne accès à une connaissance externe.
| Quand utiliser le RAG ? | Quand utiliser le fine-tuning ? |
|---|---|
| Pour intégrer des connaissances factuelles et évolutives (docs techniques, politiques internes). | Pour enseigner une compétence ou un style (adapter le ton, apprendre un format de code spécifique). |
| Quand la traçabilité et la vérifiabilité des sources sont primordiales. | Quand le modèle doit acquérir un comportement ou un savoir-faire implicite difficile à formaliser. |
| Quand les informations changent fréquemment et que la mise à jour doit être rapide et peu coûteuse. | Si la base de connaissances est stable et ne nécessite pas de mises à jour constantes. |
| Pour des budgets maîtrisés et des compétences en intégration standard. | Lorsque l’on dispose de jeux de données d’entraînement volumineux et de l’expertise ML nécessaire. |
Souvent, la meilleure solution est hybride : un modèle fine-tuné pour des comportements métiers précis, complété par un RAG pour accéder à des connaissances factuelles et actualisées.
Les défis d’un projet RAG réussi
Si le potentiel du Retrieval-Augmented Generation est considérable, une approche trop simple aboutit souvent à des résultats décevants. Réussir implique d’anticiper plusieurs défis majeurs.
- La qualité des données sources.
Un système RAG dépend directement des données qu’il consulte. Des informations obsolètes, contradictoires ou mal structurées produiront inévitablement des réponses de faible qualité. Un travail de préparation et une bonne gouvernance des données sont indispensables. - La complexité de l’architecture et la latence.
Le pipeline RAG (ingestion, embedding, indexation, recherche, génération) comprend de nombreux composants. Les optimiser pour obtenir des réponses rapides et pertinentes nécessite une expertise pointue. Une latence excessive nuit à l’expérience utilisateur. - La mesure de la performance.
Comment s’assurer de l’efficacité de votre RAG ? Évaluer la pertinence des documents récupérés et la qualité de la réponse est un enjeu complexe, qui va au-delà des métriques classiques. - La sécurité et la gouvernance des accès.
Il est impératif de garantir le respect strict des droits d’accès aux documents, surtout avec des données sensibles.
Un rapport de Valprovia met en lumière ces obstacles, qui appellent une approche réfléchie et une expertise solide pour être surmontés.
Ces défis vous paraissent familiers ? Évaluons ensemble comment une approche sur mesure peut les transformer en opportunités.
Mettre en place le RAG : l’approche sur mesure de Schneider AI
Face à ces enjeux, une approche standardisée révèle vite ses limites. Notre conviction est claire : un projet RAG performant ne s’achète pas « sur étagère », il se construit main dans la main avec vous. Chez Schneider AI, nous ne vendons pas de logiciel ; nous co-construisons des solutions sur mesure.
L’importance de la co-construction pour un RAG performant
Notre méthode repose sur la co-construction. Plutôt qu’imposer une solution toute faite, nos experts seniors, présents en France, en Suisse et connectés à la Silicon Valley, collaborent avec vos équipes métier et techniques.
Cette proximité garantit que le système RAG s’aligne parfaitement avec vos objectifs, s’intègre à votre existant et est pleinement adopté par les utilisateurs. En ciblant vos besoins spécifiques, nous assurons un véritable retour sur investissement.
Étude de cas : l’agent « Georges », de SaaS obsolète à IA rentable
Un de nos clients, une PME industrielle, utilisait une solution SaaS coûteuse et rigide pour répondre aux questions techniques de ses salariés. L’outil était lent, souvent imprécis et demeurait incapable d’intégrer les nouvelles documentations produits.
Ensemble, nous avons conçu « Georges », un agent d’intelligence artificielle interne basé sur une architecture RAG personnalisée. En connectant un LLM à l’ensemble de leur documentation technique (PDF, plans, fiches de sécurité), Georges fournit aujourd’hui des réponses instantanées, précises et sourcées.
Les résultats sont sans appel :
- Production de réponses 10x plus rapide
- Coût 5x inférieur à l’ancienne solution SaaS
Questions fréquentes sur le RAG (FAQ)
Quelle est la fiabilité des réponses générées par un système RAG ?
La fiabilité est bien supérieure à celle d’un LLM standard, car les réponses s’appuient sur des documents fournis et vérifiables. Cependant, elle dépend surtout de la qualité de votre base de connaissances. Des experts comme ceux de NVIDIA soulignent ce lien direct entre qualité des données et fiabilité des réponses.
Comment gérer les hallucinations si les données récupérées sont incorrectes ?
La meilleure défense reste une gouvernance des données rigoureuse : assurez-vous que vos sources sont fiables et à jour. Un RAG bien conçu doit aussi permettre de remonter facilement à la source de l’information pour corriger les éventuelles erreurs.
Quelles sont les bonnes pratiques pour maintenir la base de connaissances d’un RAG ?
Automatisez l’indexation des nouveaux documents et l’archivage des contenus obsolètes. Structurez vos données pour optimiser la recherche sémantique, et auditez périodiquement la pertinence des résultats afin d’ajuster le système si besoin.
Comment mesurer la pertinence et le ROI d’une solution RAG ?
La pertinence s’évalue à travers des métriques sur la qualité de la recherche (retrieval) et l’exactitude de la réponse. Le ROI se mesure en comparant les gains de productivité (temps économisé), la réduction des coûts (remplacement d’outils, diminution des erreurs) et l’augmentation de la satisfaction utilisateur.
